Nach dem Durcharbeiten dieses Tutorials sind Sie in der Lage:
TippLernziele
1. Die theoretischen Grundlagen der Stichprobentheorie zu erklären und anzuwenden
Sie verstehen das Konzept der i.i.d.-Zufallsvariablen (identisch und unabhängig verteilt) als fundamentale Voraussetzung für die Inferenzstatistik
Sie können beurteilen, wann diese Annahmen in praktischen Situationen verletzt werden (z.B. bei korrelierten Daten während eines Flash-Sales)
2. Den Zentralen Grenzwertsatz auf Stichprobenmittelwerte und Anteilswerte anzuwenden
Sie kennen die Verteilungseigenschaften von Stichprobenmittelwerten: \(E(\overline{X}) = \mu\) und \(Var(\overline{X}) = \frac{\sigma^2}{n}\)
Sie verstehen, warum Stichprobenmittelwerte näherungsweise normalverteilt sind, unabhängig von der zugrunde liegenden Populationsverteilung
Sie kennen das Bernoulli-Modell als Grundlage für Anteilswerte und können Erwartungswert und Varianz des Stichprobenanteils \(\hat{p}\) herleiten: \(E(\hat{p}) = p_0\) und \(Var(\hat{p}) = \frac{p_0(1-p_0)}{n}\)
Sie können beurteilen, wann die Normalapproximation für Anteilswerte gültig ist, und kennen die Faustregel \(n \cdot \hat{p} \geq 5\)
3. Konfidenzintervalle mathematisch herzuleiten und zu konstruieren
Sie beherrschen die Standardisierung von Stichprobenmittelwerten: \(Z = \frac{\overline{X}-\mu}{\sigma/\sqrt{n}}\)
Sie sind in der Lage, sowohl mit bekannter Varianz (Normalverteilung) als auch mit unbekannter Varianz (t-Verteilung) zu arbeiten
Sie können die Rücktransformation von standardisierten Werten zu Konfidenzintervallen durchführen
Sie verstehen den Unterschied zwischen dem Wald-Intervall \(\hat{p} \pm z \cdot \widehat{SE}\) und dem Wilson-Intervall und wissen, warum das Wilson-Intervall statistisch robuster ist
Sie kennen die Besonderheiten des Wilson-Intervalls: der Mittelpunkt liegt nicht bei \(\hat{p}\) und die Länge des KIs variiert von Stichprobe zu Stichprobe
4. Konfidenzintervalle statistisch korrekt zu interpretieren
Sie kennen den Unterschied zwischen Aussagen vor der Messung (Wahrscheinlichkeitsaussagen über das Verfahren) und nach der Messung (das Intervall enthält den Parameter oder nicht)
Sie verstehen die Bedeutung von Konfidenzniveau \((1-\alpha)\) und Irrtumswahrscheinlichkeit \((\alpha)\) als Eigenschaften des Konstruktionsverfahrens
Sie können KIs für Anteilswerte korrekt interpretieren und zur Überwachung von Fehlerquoten in der Praxis einsetzen
5. Konfidenzintervalle in praktischen Anwendungen zu nutzen und zu bewerten
Sie verstehen den Einfluss der Stichprobengrösse auf die Präzision (Standardfehler \(\sim \frac{1}{\sqrt{n}}\))
Sie können Konfidenzintervalle zur Qualitätskontrolle und Parameterverifikation einsetzen und kennen die Grenzen und Voraussetzungen des Verfahrens
Sie kennen den Unterschied zwischen theoretischen KIs (fixer Standardfehler) und praktischen KIs (geschätzter Standardfehler) und dessen Auswirkung auf die Länge des Intervalls
6. Konfidenzintervalle mit R effizient berechnen
Sie können t.test() für KIs des Erwartungswertes und prop.test() für KIs von Anteilswerten anwenden und die Ergebnisse extrahieren
Sie verstehen, wann binom.test() gegenüber prop.test() vorzuziehen ist (kleine Stichproben, Anteilswerte nahe 0 oder 1)
Sie können die Ergebnisse von Wald-, Wilson- und Clopper-Pearson-Intervall vergleichen und situationsgerecht die passende Methode wählen
Einleitung
Wenn wir Stichproben aus einer Grundgesamtheit (Population) ziehen, wollen wir in der Praxis Informationen über ihre charakteristischen Eigenschaften abschätzen (Punktschätzung). Nehmen wir ein praktischs Beispiel. Wir wollen die durchschnittliche Antwortzeit eines Servers messen und schicken 100 HTTP-Anfragen an zufällig ausgewählte Endpunkte und messen wie lange es jeweils dauert bis die Antwort kommt. Aus dem Mittelwert schliessen wir dann auf die generelle Eigenschaft des Servers, also mathematisch den Erwartungswert der Antwortzeit. Bestimmen wir noch die Varianz unserer Messwerte in der Stichprobe können wir auch das Streuverhalten abschätzen. Die Frage dabei ist nur: Wie unsicher ist diese Punktschätzung? Liegen unsere Werte nahe am charakteristischen Wert für den wir uns interessieren? In diesem kurzen Tutorial wollen wir diese Unsicherheit eingrenzen und quantitativ erfassen durch das Konzept der Konfidenz- oder Vertrauensintervall.
Zufallsstichproben - Aufbau und mathematische Idee
Alles beginnt mit dem Ziehen einer Stichprobe aus einer Population, z.B. durch eine Umfrage oder Messungen. Um am Ende zu den Konfidenzintervallen zu kommen, müssen wir zuerst verstehen, wie Zufallsstichprobe mathematisch beschrieben werden können und welche Idee hinter dieser Beschreibung steht. Wir werden den gesamten roten Faden der Argumentation anhand unseres Praxisbeispiels der Antwortzeiten von HTTP-Anfragen veranschaulichen. Wir schicken also 100 HTTP-Anfragen an zufällig ausgewählte Endpunkte und messen jeweils die Antwortzeit. Damit erhalten wir \(\{x_1, x_2, \dots, x_{100}\}\) Zeiten. Die mathematische Idee ist nun folgende: Wir numerieren die Einzelwerte (\(x_i\)) der Stichprobe. Wiederholen wir unsere 100 Anfragen viele Male können wir jede Stichproben als Komposition der Ausprägungen von 100 Zufallsvariablen \(X_i\) beschreiben. D.h. jede Stichprobe ist nur eine Konkretisierung des Datenvektors: \(X_1, X_2, \dots, X_n\). Welche Eigenschaften haben diese Zufallsvariablen? Jede der \(X_i\) kommt aus der gleichen Population (hier unserem Webserver, seiner Struktur und seinem Verhalten), deshalb dürfen wir annehmen, dass sie alle die gleichen charakteristischen Eigenschaften des Erwartungswertes (\(\mu\)) und Varianz (\(\sigma^2\)) der Population haben! Dies ist eine sehr grundlegende Annahme! Wir fassend deshalb nochmals zusammen:
TippDefinition der Zufallsstichprobe
Eine Stichprobe vom Umfang \(n\) kann als Komposition von Zufallsvariablen geschrieben werden: \(\{X_1, X_2, \dots, X_n\}\), die folgende Eigenschaften besitzen:
identisch verteilt
stochastisch unabhängig
Im Englischen werden diese Eigenschaften als i.i.d. in vielen Publikationen genannt: identical, independent distributed.
Diese Annahmen sind im weiteren Verlauf noch entscheident. Wird eine dieser Eigenschaften verletzt, werden die später ermittelten Konfidenzintervalle schwer interpretierbar oder gar sinnlos!
Verständnisfrage 1:
Welches der folgenden Szenarien verletzt am ehesten die Annahme, dass die Zufallsvariablen einer Stichprobe i.i.d. (identisch und unabhängig verteilt) sind?
a) Die Analyse von Webserver-Antwortzeiten während eines normalen, routinemässigen Betriebs, bei dem die Anfragen gleichmässig über den Tag verteilt sind.
b) Die Auswertung der Antwortzeiten eines Webservers während eines Flash-Sales, bei dem ein plötzlicher, starker Traffic zu zeitlich eng getakteten und korrelierten Antwortzeiten führt.
c) Die Untersuchung von zufällig ausgewählten Kreditkartentransaktionen, die aus verschiedenen geografischen Regionen stammen.
d) Die Analyse einer standardisierten Kundenumfrage, bei der alle Teilnehmer unabhängig voneinander befragt werden.
Antwort anzeigen
Richtige Antwort: b) Sind Variablen stark korreliert, sind sie häufig nicht mehr stochastisch unabhängig.
Konfidenzintervalle für Erwartungswerte
Verteilung der Stichprobenmittelwerte
Wenn wir, wie bei den Antwortzeiten, eine metrische Variable vorliegen haben, können wir das arithmetische Mittel der Stichprobe berechnen:
\[
\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i.
\] Unsere Ziel ist es mit dem Mittelwert eine zuverlässige Aussage über den unbekannten Erwartungswert, \(\mu\), der Population zu erhalten. Aus einem einzelnen Mittelwert lernen wir allerdings nichts über die Unsicherheit der Schätzung. Deshalb ist es naheliegend sehr viele Stichproben zu ziehen, jeweils den Mittelwert zu bestimmen, und sich anzusehen, wie die Werte sich verhalten. Wir wollen mit unseren Serverantwortzeiten realistisch bleiben und simulieren mit einer realitätsnahen Verteilung.
Antwortzeiten: Ein realistisches Modell für die Population
Sehr wahrscheinlich werden sehr lange Antwortzeiten unwahrscheinlicher sein als sehr kurze. In der Praxis sehen wir, dass solche Antwortzeiten häufig durch eine sog. Exponentialverteilung beschrieben werden können. Die Wahrscheilichkeitsdichte der Exponentialverteilung wird beschrieben durch:
Die Exponentialveteilung kennt nur einen Parameter, \(\lambda\). Er charakterisiert vor allem, wie rasch die Funktion abfällt.
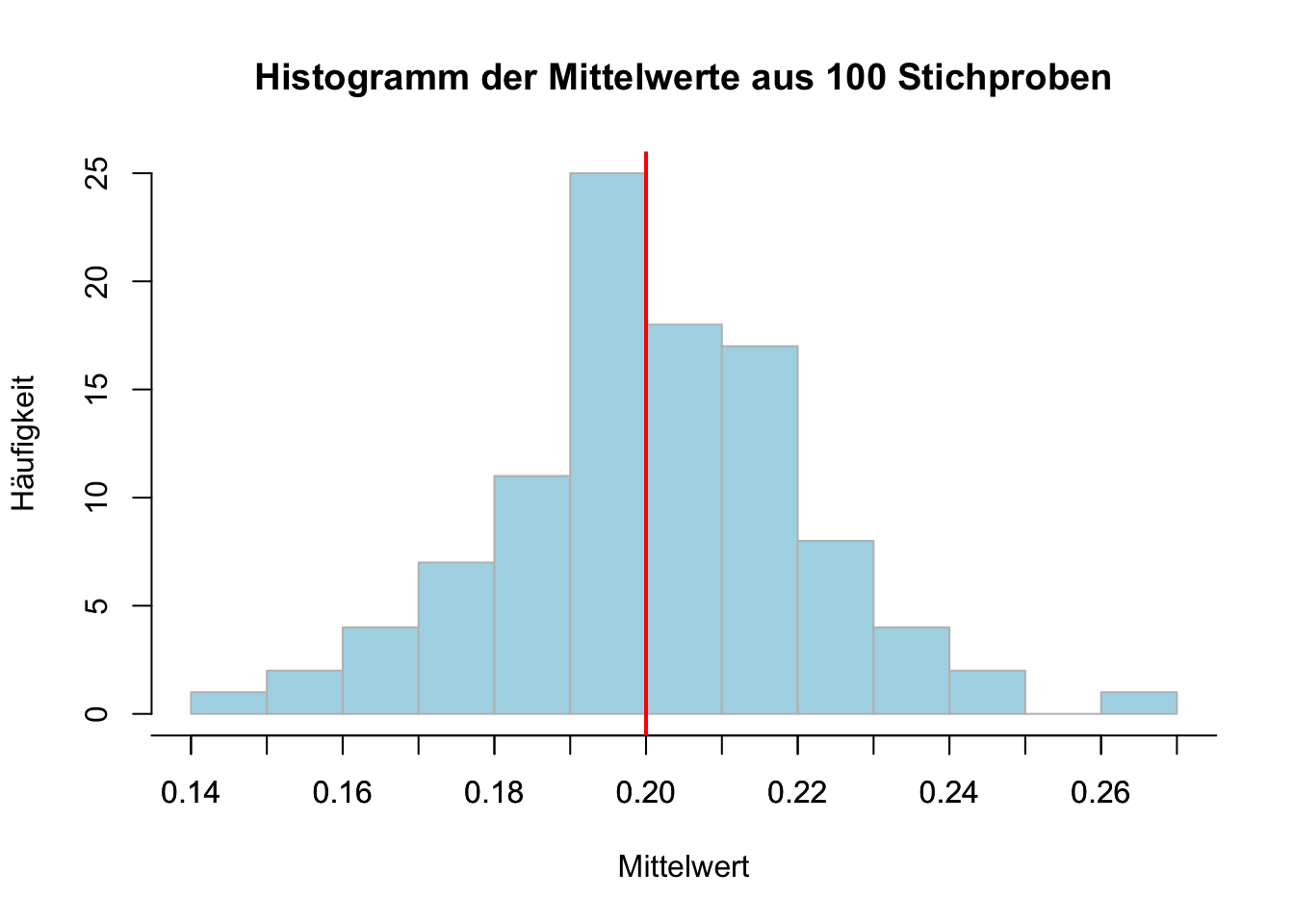
In R implementieren wir diese Verteilung mit der realistischen mittleren Antwortzeit von \(\lambda = 5 \Rightarrow E[T]=1/ \lambda = 0.2~s\) und ziehen 100 Stichproben von Umfang \(n=100\) aus dieser Population. Für jede Stichprobe wird der Mittelwert berechnet. Zum Abschluss plotten wir das Histogramm der Stichprobenmittelwerte und zeichnen den Erwartungswert der Grundgesamtheit als Referenz ein.
Code anzeigen
# Setze einen Seed für die Reproduzierbarkeit (Auswahl eine Pseudozufallsgenerators)set.seed(342)# Parameter definierenn <-100# Stichprobengrössenum_samples <-100# Anzahl der Stichprobenlambda <-5# Rate der Exponentialverteilung# Vektor zur Speicherung der Mittelwerte initialisierensample_means <-numeric(num_samples)# 100 Stichproben simulieren und deren Mittelwert berechnenfor(i in1:num_samples) { sample_data <-rexp(n, rate = lambda) sample_means[i] <-mean(sample_data)}# Histogramm der Mittelwerte plottenhist(sample_means, breaks =10, main ="Histogramm der Mittelwerte aus 100 Stichproben",xlab ="Mittelwert", col ="lightblue", border ="gray",ylab ="Häufigkeit") # automatische x-Achse unterdrücken# Definiere manuelle Achsenbeschriftungen, z.B. im Bereich 0.15 bis 0.25axis(1, at =seq(0.1, 0.3, by =0.01))# Erwartungswert 0.2 als Referenzlinie einzeichnenabline(v =0.2, col ="red", lwd =2)
Wie erwartet streuen die gemessenen Mittelwert um den wahren Erwartungsweg \(\mu\). In der Praxis würden wir uns jetzt fragen, ob unsere konkrete Stichprobe nahe an \(0.2\) oder womöglich sehr weit davon entfernt liegt? Um dies besser zu verstehen, müssen wir folgende Fragen beantworten:
WichtigWichtige Fragen
Was wissen wir über das Streuverhalten dieser Mittelwerte?
Wovon hängt das Streuverhalten ab?
Können wir es durch die Art und Durchführung der Messung beeinflussen?
Streuverhalten der Mittelwerte - Bedeutung des Zentralen Grenzwertsatz
Wir haben bei der Diskussion des Zentralen Grenzwertsatzes (ZGS) gelernt, dass die Mittelwerte der Stichproben, die aus eine beliebigen Grundgesamtheit gezogen werden bei ausreichend grosser Stichprobegrösse nahezu normalverteilt streuen. Diese Eigenschaft ist zentral um zu verstehen, wie wir weiter vorgehen.
Wir erwarten, dass der Erwartungswerte unserer Mittelwerte (\(E(\overline{X})\)) mit \(\mu\) der Population übereinstimmt. Überprüfen wir:
Hier haben wir zwei wichtige Eigenschaften ausgenutzt:
Die Berechnung des Erwartungswertes angewandt auf eine Summe von Zufallsvariablen können wir auch durch Berechnung des Mittelwertes aller einzelnen Erwartungswerte durchführen (Anm. man nennt das in der Mathematik auch eine lineare Eigenschaft des Operators Erwartungswert)
die zweite Eigenschaft ist die der “i.i.d”, d.h. alle haben den gleichen Erwartungswert
Hier sehen wir auch, warum die i.i.d. auch eine intuitiv gut nachvollziehbare Annahme ist, denn wir erwarten natürlich, dass die gemessenen Mittelwerte bei einer sehr grossen Anzahl Stichproben im Mittel gegen \(\mu\) streben.
Diese ist nur möglich, weil für die Berechnung der Varianz gilt: \[
Var(aX) = a^2 Var(X)
\] Auch dies ist eine sog. lineare Eigenschaft, diesmal der Varianz. Im Modul lineare Algebra werden wir solche linearen Operatoren genauer ansehen.
Nun kennen wir den Zusammenhang zwischen den Eigenschaften der Population und denen der Verteilung der Stichprobenmittelwerte. Durch den ZGS wissen wir aber noch mehr! Die Mittelwerte müssen näherungsweise normalverteilt sein.
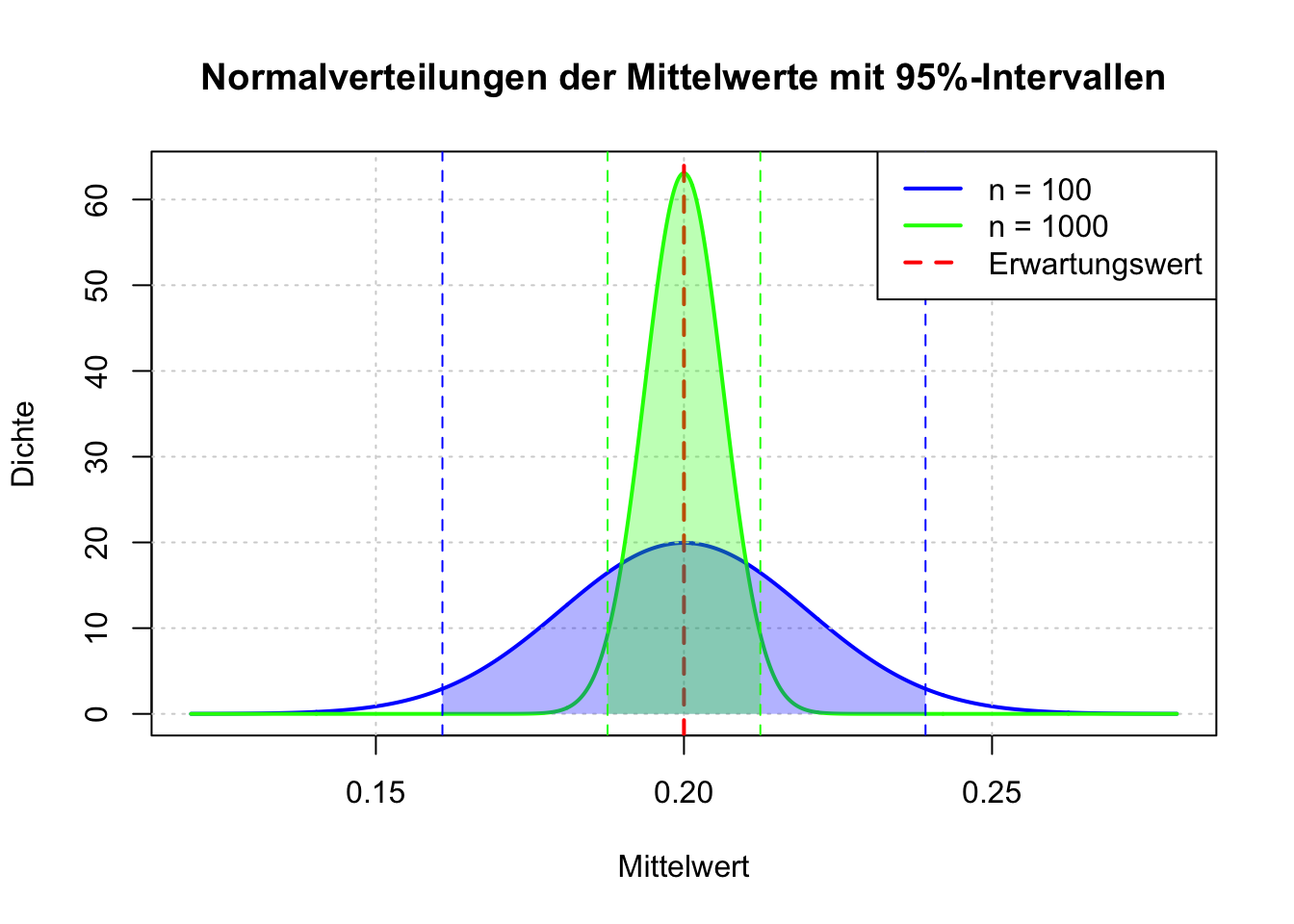
Wir können folglich die Unsicherheit unserer Messung durch die Grösse der Stichprobe mit der Abhängigkeit \(\sim \frac{1}{n}\) verändern, wie wir in der nachfolgenden Visualisierung für \(n=100\) und \(n=1000\) sehr gut beobachten können.
Code anzeigen
# Parameter für die Normalapproximation der Mittelwerte:mean_val <-0.2se1 <-0.2/sqrt(100) # Stichprobenumfang n = 100se2 <-0.2/sqrt(1000) # Stichprobenumfang n = 1000# Berechne die 95%-Quantile für beide Verteilungen:alpha <-0.05lower1 <-qnorm(alpha /2, mean = mean_val, sd = se1)upper1 <-qnorm(1- alpha /2, mean = mean_val, sd = se1)lower2 <-qnorm(alpha /2, mean = mean_val, sd = se2)upper2 <-qnorm(1- alpha /2, mean = mean_val, sd = se2)# Wähle einen x-Bereich, der beide Kurven abdeckt.# Da die breitere Kurve (n = 100) mehr Streuung hat, orientieren wir uns daran:x <-seq(mean_val -4* se1, mean_val +4* se1, length.out =1000)# Berechne die Dichten:y1 <-dnorm(x, mean = mean_val, sd = se1)y2 <-dnorm(x, mean = mean_val, sd = se2)# Plot der Dichte für n = 100 (blau)plot(x, y1, type ="l", lwd =2, col ="blue",ylim =c(0, max(y1, y2)),main ="Normalverteilungen der Mittelwerte mit 95%-Intervallen",xlab ="Mittelwert", ylab ="Dichte")grid()# Füge die Dichte für n = 1000 (grün) hinzu:lines(x, y2, type ="l", lwd =2, col ="green")# Zeichne den theoretischen Erwartungswert als vertikale Referenzlinie:abline(v = mean_val, col ="red", lwd =2, lty =2)# Schattiere die 95%-Konfidenzintervalle:# Für n = 100 (blauer Schattierungsbereich)x_blue <-seq(lower1, upper1, length.out =200)y_blue <-dnorm(x_blue, mean = mean_val, sd = se1)polygon(c(lower1, x_blue, upper1), c(0, y_blue, 0),col =rgb(0, 0, 1, 0.3), border =NA)# Für n = 1000 (grüner Schattierungsbereich)x_green <-seq(lower2, upper2, length.out =200)y_green <-dnorm(x_green, mean = mean_val, sd = se2)polygon(c(lower2, x_green, upper2), c(0, y_green, 0),col =rgb(0, 1, 0, 0.3), border =NA)# Füge die kritischen Werte als gestrichelte Linien hinzu:abline(v = lower1, col ="blue", lwd =1, lty =2)abline(v = upper1, col ="blue", lwd =1, lty =2)abline(v = lower2, col ="green", lwd =1, lty =2)abline(v = upper2, col ="green", lwd =1, lty =2)# Legende hinzufügen:legend("topright", legend =c("n = 100", "n = 1000", "Erwartungswert"),col =c("blue", "green", "red"), lwd =2, lty =c(1, 1, 2))
Damit haben wir jetzt eine gute Vorstellung, wie unsere Stichprobenmittelwerte in Abhängigkeit vom Stichprobenumfang um den Erwartungswert streuen.
Jetzt kommen wir zur Kernidee der Konfidenzintervalle. Bevor wir diese vollständig erklären können, müssen wir unsere Zufallsvariable \(\overline{X}\) noch auf die Standardnormalverteilung standardisieren, d.h. dass wir eine neue Zufallsvariable \(Z\) definieren, deren Erwartungswert \(E(Z) = 0\) und die Varianz \(Var(Z)=1\) ist.
Standardisierung des Stichprobenmittels (bei bekannte Varianz \(\sigma^2\))
Ist die Varianz \(\sigma^2\) bekannt, kann das Mittel \(\overline{X}\) standardisiert werden. Die Standardisierung erfolgt durch Subtraktion des Erwartungswerts und Division durch die Standardabweichung des Mittelwerts:
\[
Z = \frac{\bar{X} - \mu}{\sigma/\sqrt{n}}.
\]
Da \(\overline{X}\) normalverteilt ist, folgt:
\[
Z \sim \mathcal{N}(0,1).
\]
Wichtig
Warum müssen wir standardisieren? Durch die Standardisierung erhalten wir mit \(Z\), eine Zufallsvariable, deren Verteilung unabhängig von den Parametern \(\mu\) und \(\sigma\)undstandardnormalverteilt ist! Das erlaubt es uns, Quantile der Standardnormalverteilung zu verwenden, um Wahrscheinlichkeiten zu bestimmen.
Konfidenzniveau und Irrtumswahrscheinlichkeit
Jetzt sind wir parat um die Kernidee des Konfidenzintervalls zu diskutiern.
Wenn wir mit \(Z\) arbeiten, können wir vor dem Ziehen der Stichprobe angeben, in welchen symmetrischen Bereich um** \(\mu\) herum sich der Mittelwert mit z.B. \(95\%\)-Wahrscheinlichkeit befinden wird, wie im vorherigen Diagramme für die blaue Verteilung mit den vertikalen Strichen dargestellt ist. Diesem Wert von \(95\%\) geben wir einen eigenen Namen: Konfidenzniveau, weil wir mit dieser Wahrscheinlichkeit sicher (konfident) sind, dass der zumessenden Mittelwert in diesen Bereich fällt. Der Differenz zu \(100\%\) geben wir auch einen eigenen Namen: Irrtumswahrscheinlichkeit, \(\alpha\), d.h. die Wahrscheinlichkeit, dass wir uns irren und der Mittelwert ausserhalb des Bereichs liegt.
WichtigWichtige Definitionen
Konfidenzniveau\(1-\alpha\):
Das Konfidenzniveau gibt an, in welchem vorher definierten symmetrischen Bereich um den wahren Erwartungswert \(\mu\) sich der Stichprobenmittelwert \(\overline{X}\) mit einer festgelegten Wahrscheinlichkeit befinden wird.
Irrtumswahrscheinlichkeit\(\alpha\):
Die Irrtumswahrscheinlichkeit \(\alpha\) beschreibt den Anteil der Fälle, in denen der Mittelwert nicht in diesen symmetrischen Bereich fällt.
Konstruktion des Konfindezintervalls (KI)
Gut, aber wie berechnet man die Grenzen dieses Bereichs (oder Intervalls)?
Wir überlegen folgendes: Der Bereich liegt symmeterisch um den Erwartungswert und die Fläche unter der Standardnormalverteilung beträgt \(95\%\) der Gesamtwahrscheinlichkeit.
Mathematisch formuliert:
\[
P\left(-z_{1-\alpha/2} \le Z \le z_{1-\alpha/2}\right) = 1-\alpha\\
\] Für unser konkretes Beispiel der Antwortzeiten mit einem \(\alpha=0.05\): \[
P\left(-z_{0.975} \le Z \le z_{0.975}\right) = 0.95
\]
In Worten: Die Wahrscheinlichkeit, dass der Wert von \(Z\) im Intervall (der Quantilen) \([-z_{0.975}, z_{0.975}]\) liegt, beträgt \(95\%\). Also werden links und rechts jeweils \(\alpha/2 = 2.5\%\) der Wahrscheinlichkeit ausserhalb des Bereichs liegen. Die Grenzen selbst, sind in unserem Beispiel folglich die \(2.5\%\) bzw. \(97.5\%\)Quantilen der Standardnormalverteilung: \(\pm z_{\alpha/2}\).
Da wir uns aber nicht für die transformierte Variable, \(Z\), sondern für \(\overline{X}\) interessieren, müssen wir jetzt zurücktransformieren auf \(\overline{X}\):
Formen wir die Doppelungleichung so um, dass \(\mu\) in der Mitte alleine steht: m \[
-z_{1-\alpha/2} \le \frac{\overline{X}-\mu}{\sigma/\sqrt{n}} \le z_{1-\alpha/2} |\cdot \sigma/\sqrt{n}; - \overline{X}; \cdot (-1)
\] erhalten wir:
\[
\overline{X} - z_{1-\alpha/2}\cdot \frac{\sigma}{\sqrt{n}} \le \mu \le \overline{X} + z_{1-\alpha/2} \cdot \frac{\sigma}{\sqrt{n}}
\] in unserem konkreten Fall der Antwortzeiten: \[
\overline{X} - 1.96 \cdot \frac{0.2}{\sqrt{100}} \le \mu \le \overline{X} + 1.96 \cdot \frac{0.2}{\sqrt{100}}
\] Was lernen wir aus dieser Ungleichung?
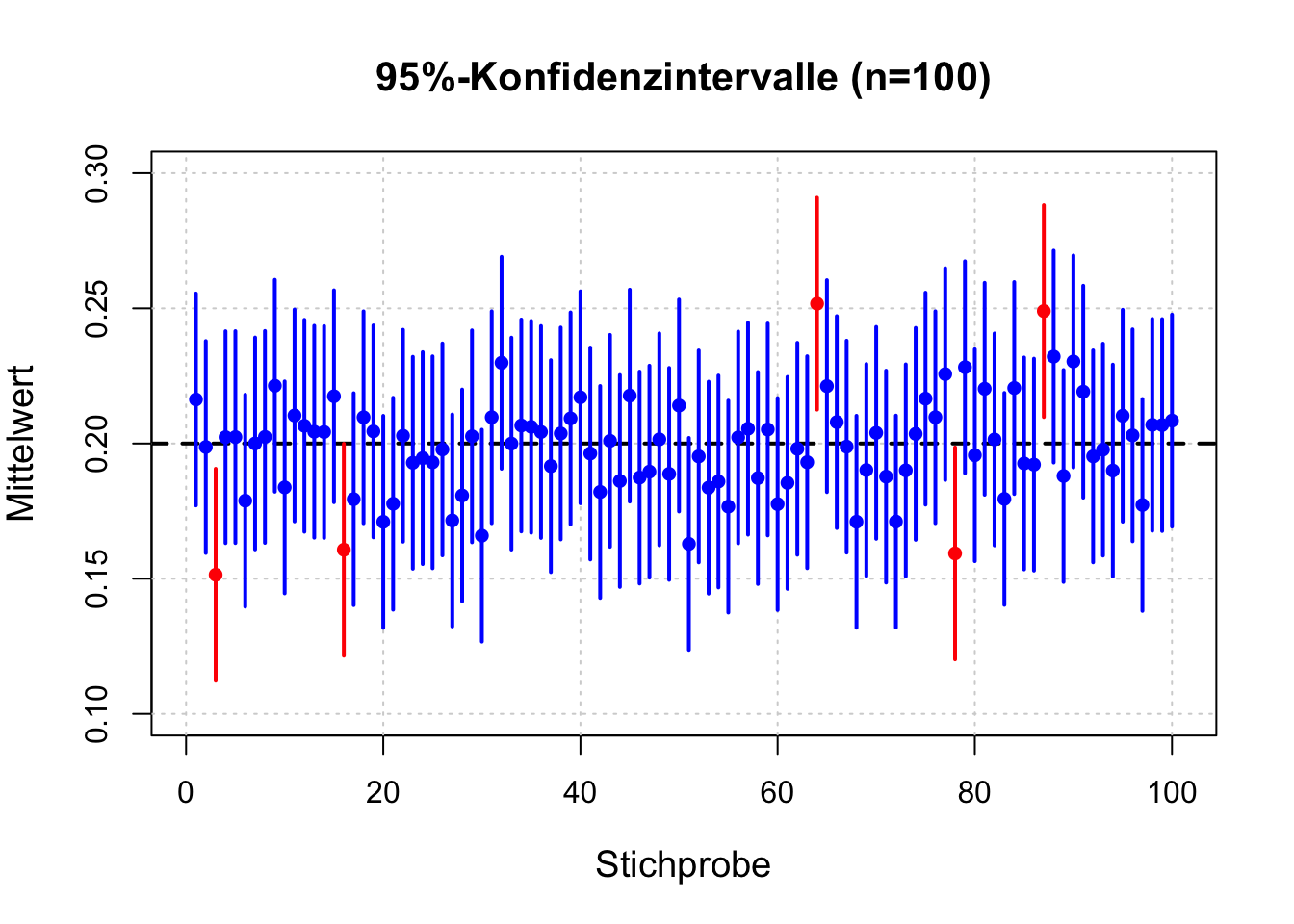
Statt weiter theoretische Argumente zu diskutieren, wollen wir stattdessen eine Simulation mit 100 Stichproben durchführen und für jede Stichprobe dieses Intervall bestimmen und alle Intervalle visualisieren.
Code anzeigen
# Setze den Seed für Reproduzierbarkeitset.seed(223)# Parameter festlegenn <-100# Stichprobengrössenum_samples <-100# Anzahl der Stichprobenlambda <-5# Rate der Exponentialverteilungmu <-1/ lambda # Erwartungswert, 0.2sigma <-1/ lambda # Standardabweichung, 0.2 (Exponentialverteilung)# DataFrame zur Speicherung: Stichproben, Mittelwert und 95%-KonfidenzintervallCI <-data.frame(sample =1:num_samples,xbar =numeric(num_samples),lower =numeric(num_samples),upper =numeric(num_samples))# Für jede Stichprobe: Mittelwert und 95%-KI berechnenfor (i in1:num_samples) { sample_data <-rexp(n, rate = lambda) xbar <-mean(sample_data) se <- sigma /sqrt(n) # Standardfehler: 0.2/sqrt(100) = 0.02 lower_ci <- xbar -1.96* se # 95%-KI untere Grenze upper_ci <- xbar +1.96* se # 95%-KI obere Grenze CI[i, "xbar"] <- xbar CI[i, "lower"] <- lower_ci CI[i, "upper"] <- upper_ci}# Plot vorbereiten: x-Achse = Stichproben (1 bis 100), y-Achse = Mittelwertbereichplot(NA, xlim =c(0.5, num_samples +0.5), ylim =c(0.10, 0.30),xlab ="Stichprobe", ylab ="Mittelwert",main ="95%-Konfidenzintervalle (n=100)",cex.lab =1.2, cex.main =1.3)grid()# Zeichne den wahren Erwartungswert als horizontale Referenzlinieabline(h = mu, col ="black", lwd =2, lty =2)# Zeichne für jede Stichprobe das Konfidenzintervall als vertikale Linie:# Intervalle, die das wahre μ nicht enthalten, werden in Rot, sonst in Blau.for (i in1:num_samples) {if (CI$lower[i] > mu | CI$upper[i] < mu) { col_line <-"red"# KI enthält \mu nicht } else { col_line <-"blue"# KI enthält \mu }segments(x0 = CI$sample[i], y0 = CI$lower[i],x1 = CI$sample[i], y1 = CI$upper[i],col = col_line, lwd =2)# Markiere den Stichprobenmittelwert als Punktpoints(CI$sample[i], CI$xbar[i], pch =16, col = col_line)}
Hier sehen wir jetzt nochmals die Bedeutung des \(95\%\) Konfidenzniveaus. Wir hatten vor der Messung gesagt, dass es genau diese Wahrscheinlichkeit gibt \(\mu\) im zu messenden Intervall zu finden. Das bestätigt die Simulation eindrücklich. \(95\) der Intervalle enthalten \(\mu\) und fünf nicht! Diese Intervalle nennen wir jetzt Konvidenz- oder Vertrauensintervalle (KI).
Wichtig
Würden wir nochmals 100 Stichproben ziehen, können aber auch nur \(94\) oder \(96\) Intervalle \(\mu\) enthalten. Im Mittel enthalten \(95\%\) der Intervalle den Erwartungswert!
Interpretation von Konfindenzintervallen des Erwartungswertes
Wie arbeiten und interpretieren wir diese Intervalle?
In der Praxis werden wir keine 100 Stichproben ziehen, sondern nur einige wenige oder gar nur eine. Angenommen wir ziehen eine Stichprobe und erhalten \(\overline{x} \approx 0.14\), dann berechnen wir das KI zu:
Wenn wir das KI einmal gestimmt haben, dann kann es entweder zu jenen gehören, die \(\mu\) enthalten oder eben nicht. Nach der Messung gibt es keine Wahrscheinlichkeit mehr zu bestimmen, alles ist festgelegt! Das ist der Grund, warum die folgende Aussage (die man in vielen Lehrbüchern und Publikationen finden kann) konzeptionell falsch ist:
“Es gibt eine\(95\%\) Wahrscheinlichkeit den Erwarungswert \(\mu\) im Intervall \(KI = [0.210 \pm 0.0392]\) zu finden.”
Dies können wir nur vor der Messung sagen!
Korrekt halten wir deshalb fest:
TippDefinition des Vertrauensintervalls (Konfidenzintervalls)
Ein \((1-\alpha)\)-Konfidenzintervall ist ein auf Basis von Stichprobendaten berechnetes Intervall \([U, O]\), das bei erfüllten Verteilungsannahmen folgende Eigenschaft besitzt: Bei wiederholter Ziehung von Stichproben gleichen Umfangs und entsprechender Berechnung des Intervalls enthält ein Anteil von mindestens \((1-\alpha)\) aller so konstruierten Intervalle den wahren Parameter \(\theta\) (z.B. den Erwartungswert \(\mu\)).
Mathematisch:\(P(U \leq \theta \leq O) \geq 1-\alpha\), wobei \(U\) und \(O\) Funktionen der Stichprobe und somit vor der Datenerhebung Zufallsvariablen sind.
Wichtige Interpretation
Vor der Stichprobenziehung: Das zu berechnende Intervall ist zufällig, der Parameter \(\theta\) ist fest.
Nach der Berechnung: Das Intervall ist fest und enthält entweder den wahren Parameter oder nicht! Es gibt dann keine Wahrscheinlichkeitsaussage mehr für dieses einzelne, realisierte Intervall.
Die \((1-\alpha)\)-Angabe (z.B. 95%) bezieht sich auf die grundlegende Eigenschaft des Konstruktionsverfahrens: Bei sehr vielen Wiederholungen des gesamten Prozesses (Stichprobenziehung → Intervallberechnung) würde dieser Anteil der Intervalle den wahren Wert einschließen.
Voraussetzungen
Verteilungsannahmen: Entweder bekannte Grundgesamtheitsverteilung (z.B. Normalverteilung mit \(\sigma\)) oder Gültigkeit des Zentralen Grenzwertsatzes (ZGS) bei unbekannter Verteilung
Für ZGS: Unabhängige, identisch verteilte Beobachtungen (i.i.d.), Existenz von Erwartungswert und Varianz, ausreichend große Stichprobe
Kommen wir nochmals zu unseren Messungen der Antwortzeiten zurück. Angenommen wir wissen, dass der neue Server tatsächlich genau den Erwartungswert \(\mu = 0.2 s\) für die Antwortzeiten besass, als er in Betrieb genommen wurde. Nun haben wir nach einem Jahr nochmals eine Messung gemacht und \(KI=[0.101, \; 0.179]\) erhalten. Wie interpretieren wir diesen Befund? \(0.2 s\) liegt nicht im KI. D.h. wir sollten nicht davon aussgehen, dass der Erwartungswert immer noch bei \(0.2 s\) ist.
Warum? Wir wissen, dass vor jeder Messung eine \(95\%\)-ige Wahrscheinlichkeit besteht, dass unser zubestimmende KI den wahren Wert enthält, also \(0.2\). Liegt er dann nicht darin, können wir zumindest sagen, dass nur eine \(5\%\) Wahrscheinlichkeit für diesen Fall ursprünglich bestand. Das ist relativ gering. Die Vermutung liegt also nahe, dass sich die Eigenschaften des Servers verändert haben. Dieser Fall tritt auch häufig in der Qualitätssicherung der Fertigung ein, wo z.B. Maschinen kalibriert werden um bestimmte Toleranzen einzuhalten. Hier werden KIs bestimmt, um einen voher bestimmten Parameter (z.B. Erwartungswert) zu verifizieren. Stimmen beispielsweise noch die 1000 ml Abfüllvolumen einer Mineralwasserabfüllanlage oder brauchten wir eine neu Kalibierung.
Verständnisfrage 2:
Welchen Effekt hat eine Erhöhung der Stichprobengrösse auf das Konfidenzintervall?
a) Mit zunehmender Stichprobengrösse wird das Konfidenzintervall breiter.
b) Mit zunehmender Stichprobengrösse bleibt die Breite des Konfidenzintervalls unverändert.
c) Mit zunehmender Stichprobengrösse wird die Länge des KIs schmaler.
d) Die Stichprobengrösse hat keinen Einfluss auf das Konfidenzintervall, solange die Population konstant bleibt.
Antwort anzeigen
Richtige Antwort: c) Wird n erhöht sammeln wir mehr Information über die Population. Dadurch wird die Unsicherheit reduziert und das KI schmaler. Mathmatisch skaliert die Länge mit \(\sim 1/\sqrt{n}\)
Was, wenn wir die Varianz (\(\sigma^2\)) der Grundgesamtheit nicht kennen?
Wir haben bei unserem Beispiel ganz selbstverständlich vorausgesetzt, dass wir \(\sigma^2\) der Population kennen. Das ist in der Praxis häufig nicht der Fall. In diesem Fall verwenden wir dann in der Regel nicht die Normalverteilung, sondern die t-Verteilung, besonders, wenn wir keine so grossen Stichproben zur Verfügung haben. Die Logik der Argumentation und Rechnung bleibt die gleiche, wie bei der Normalverteilung.
Der Fall der unbekannten Varianz (mit t-Verteilung)
Ist die Varianz \(\sigma^2\) unbekannt, schätzen wir sie mit der Stichprobenvarianz:
betrachtet. Es lässt sich zeigen, dass \(T\) der t-Verteilung mit \(n-1\) Freiheitsgraden folgt:
\[
T \sim t_{n-1}.
\]
WichtigBegründung
Die t-Verteilung berücksichtigt den zusätzlichen Fehler, der durch die Schätzung der Varianz entsteht. Für kleinere Stichproben ist \(s\) ein weniger präziser Schätzer für \(\sigma\), weshalb die t-Verteilung im Vergleich zur Normalverteilung breitere Quantile aufweist.
Analog zum z-Fall (Standardnormalverteilung) schreiben wir:
\[
P\left(-t_{\alpha/2,n-1} \le T \le t_{\alpha/2,n-1}\right) = 1-\alpha.
\]
Auch hier wird zunächst das Stichprobenmittel \(\overline{X}\) standardisiert. Da die Varianz unbekannt ist, wird \(s\) anstelle von \(\sigma\) verwendet, was zu einer t-Verteilung führt. Der kritische Wert \(t_{\alpha/2,n-1}\) passt sich der Stichprobengrösse (bzw. den Freiheitsgraden) an und sorgt dafür, dass das Intervall exakt die gewünschte Sicherheit \(1-\alpha\) bietet.
Ergänzung: Standardfehler
Die Länge der Konfidenzintervalle wird durch die Standardabweichung der Verteilung der Mittelwerte: \(Var(\overline{X})=\frac{\sigma}{\sqrt{n}}\) bestimmt. Dieser Standabweichung gibt mein einen eigenen Namen: Standardfehler.
TippDefinition: Standardfehler
Der Standardfehler des Stichprobenmittelwerts ist ein Mass für die Streuung der Mittelwerte, die bei wiederholter Ziehung von Stichproben aus einer Grundgesamtheit entstehen. Er wird definiert als
\[
\text{SE} = \frac{\sigma}{\sqrt{n}},
\]
wobei \(\sigma\) die Standardabweichung der Grundgesamtheit und \(n\) der Stichprobenumfang ist. Der Standardfehler gibt an, wie stark der Mittelwert \(\overline{X}\) typischerweise um den wahren Erwartungswert \(\mu\) schwankt. Ein kleiner Standardfehler weist auf eine präzisere Schätzung von \(\mu\) hin, was bei grösseren Stichproben der Fall ist.
Wenn die wahre Standardabweichung \(\sigma\) der Grundgesamtheit nicht bekannt ist, wird \(\sigma\) durch die Stichprobenstandardabweichung \(s\) ersetzt. In diesem Fall wird der Standardfehler des Mittelwerts wie folgt definiert:
\[
\text{SE} = \frac{s}{\sqrt{n}},
\]
wobei \(s\) die Standardabweichung der Stichprobe und $ n $ der Stichprobenumfang ist. Dieser geschätzte Standardfehler gibt an, wie stark der Mittelwert \(\overline{X}\) typischerweise um den wahren Erwartungswert \(\mu\) schwankt, wenn \(\sigma\) unbekannt ist.
Verständnisfrage 3:
Wie wirkt sich die Verwendung der Stichprobenstandardabweichung \(s\) anstelle der Populationsstandardabweichung \(\sigma\) auf das Konfidenzintervall aus?
a) Das Konfidenzintervall bleibt unverändert, da \(s\) immer ein guter Schätzer für \(\sigma\) ist.
b) Das Konfidenzintervall wird tendenziell breiter, weil \(s\) zusätzlich die Schätzunsicherheit mit einbezieht.
c) Das Konfidenzintervall wird schmaler, da \(s\) die Daten besser widerspiegelt.
d) Es gibt keinen Einfluss, da \(s\) und \(\sigma\) mathematisch identisch sind.
Antwort anzeigen
Richtige Antwort: b) Anm.: Wenn man nun die KIs für mehrere Stichproben berechnet, dann variiert die Länge des KIs, da jede Stichprobe eine leicht andere Stichprobenvarianz aufweist.
Zusammenfassung der Konzepte
Stichprobentheorie
Jede Stichprobe ist aus \(n\) unabhängigen, identisch verteilten Zufallsvariablen (i.i.d.) zusammengesetzt: \(X_1, X_2, \dots, X_n\)
Standardisierung:
Um den Stichprobenmittelwert \(\overline{X}\) unabhängig von \(\mu\) und \(\sigma\) zu betrachten, wird er standardisiert. Dadurch erhält man Zufallsvariablen mit bekannten Verteilungen (\(\mathcal{N}(0,1)\) oder \(t_{n-1}\)).
Kritische Quantile:
Die Werte \(z_{\alpha/2}\) bzw. \(t_{\alpha/2,n-1}\) bestimmen den Randbereich, in dem der standardisierte Wert liegen muss, um ein Konfidenzniveau von \(1-\alpha\) zu erreichen.
Rücktransformation:
Durch Umstellen der Ungleichungen erhält man schliesslich das Konfidenzintervall um den Stichprobenmittelwert.
Einfluss der Stichprobengrösse:
Der Term \(\sigma/\sqrt{n}\) (bzw. \(s/\sqrt{n}\)) zeigt, dass bei grösserem \(n\) der Standardfehler kleiner wird und damit das Konfidenzintervall enger.
Konfidenzintervalle für Anteilswerte
In vielen Fällen interessieren wir uns nicht für den Mittelwert einer Messgröße (wie die Antwortzeit), sondern für die Häufigkeit eines Ereignisses. In unserem Server-Beispiel könnte dies die Fehlerquote sein: Wie hoch ist der Anteil der Anfragen, die mit einem Fehler (z.B. Status 500 - Internal Server Error`) beantwortet werden?
Das mathematische Modell: Von Bernoulli zur Binomialverteilung
Versuchen wir diese Situation anschaulich zu verstehen. Wenn wir eine einzelne Anfrage betrachten, gibt es nur zwei Möglichkeiten: Erfolg (\(0\)) oder Fehler (\(1\)). Dies können wird durch eine Bernoulli-Zufallsvariable\(X_i\) mit dem Parameter \(p_0\) beschreiben, der die wahre (aber unbekannte) Eintrittswahrscheinlichkeit und damit die Fehlerquote der Grundgesamtheit darstellt:
In der Praxis haben wir keine Kenntnis von \(p_0\), also bleibt nur die Schätzung aus dem Anteilswert der Stichprobe, \(\hat p = X/n\). Wir approximieren wieder mit Normalverteilung und der näherungsweisen Gültigkeit des Zentralen Grenzwertsatzes! Dies geht wieder nur, wenn der Stichprobenumfang \(n\) ausreichend gross ist. Die Bedingung schauen wir uns nach der Herleitung an. Unser Zufallsvariable nenne wir \(Z_n\). Sie wird aus der Differenz von \(\hat{p}-p_0\) berechnet, die wir noch auf eine Varianz von \(1\) normieren:
\[Z_n = \frac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}} \sim \mathcal N(0,1).\] Mit den ZGS gehen wir wieder davon aus, dass sie standardnormalverteilt ist.
Mit (\(z = z_{1-\alpha/2}\)) folgt:
\[P\left( - z \le \frac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}} \le z \right) \approx 1-\alpha\] Jetzt müssen wir aufpassen, denn beim Erwartungswert \(\mu\) war die Auflösung einfach. Beim Anteilswert haben wir jedoch eine Wurzel im Nenner und\(p_0\) kommt sowohl in Zähler wie im Nenner vor! Das wird am Ende zu einer wesentlich komplizierteren Formel und Interpretation führen. \[
- z \le \frac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}} \le z
\]\[
\Leftrightarrow \left( \frac{\hat p - p_0}{\sqrt{p_0(1-p_0)/n}}\right)^2 \le z^2
\]\[
\Leftrightarrow (\hat p - p_0)^2 \le z^2\cdot \frac{p_0(1-p_0)}{n}
\] Wir lösen in mehreren Schritten nach \(\hat{p}\) auf. Wer die Schönheit der Algebra überspringen möchte, kann direkt zum Endresultat, dem Wilson-Konfidenzintervall gehen.
Diese Intervall besitzt eine viel kompliziertere Definition jenes für den Erwartungswert. Was fällt auf?
Mittelpunkt des Intervalls: \[
\text{Mittelpunkt des KIs}=
\frac{
\hat p + \frac{z^2}{2n}
}{
1+\frac{z^2}{n}
}
\]
Der Mittelpunkt liegt nicht einfach bei \(\hat p\). Sowohl die Quantile \(z\) als auch der Stichprobenumfang \(n\) haben einen Einfluss. Dieser verschwindet jedoch bei grossen Stichproben.
Verständnisfrage 4:
Worin unterscheidet sich der Mittelpunkt des Wilson-Konfidenzintervalls vom einfachen Stichprobenanteil \(\hat{p}\)?
a) Der Mittelpunkt ist immer kleiner als \(\hat{p}\), weil die Wilson-Formel eine Korrektur nach unten vornimmt.
b) Der Mittelpunkt liegt nicht bei \(\hat{p}\), sondern wird durch \(n\) und das Quantil \(z\) beeinflusst — dieser Effekt verschwindet aber bei grossen Stichproben.
c) Wilson und Wald haben denselben Mittelpunkt, sie unterscheiden sich nur in der Länge des Intervalls.
d) Der Mittelpunkt des Wilson-Intervalls ist immer \(0.5\), unabhängig von \(\hat{p}\).
Antwort anzeigen
Richtige Antwort: b) Der Mittelpunkt berechnet sich als \((\hat{p} + z^2/(2n)) / (1 + z^2/n)\). Für grosse \(n\) geht \(z^2/n \to 0\) und der Mittelpunkt nähert sich \(\hat{p}\) an.
Länge des Konfidenzintervalls: \[
\text{Länge des KIs}= 2z
\frac{
\sqrt{\frac{\hat p(1-\hat p)}{n}+\frac{z^2}{4n^2}}
}{
1+\frac{z^2}{n}
}
\] Mit der gleichen Überlegung, wie bei \(\mu\), nämlich dass wir \(n\) i.i.d. Stichproben ziehen, können wir den Standardfehler herleiten für den Anteilswert:
\[
\begin{aligned}
Var(p_0) &= Var\left(\frac{1}{n} \sum_{i=1}^n X_i\right) \\
&= \frac{1}{n^2} \sum_{i=1}^n Var(X_i) \quad (\text{wegen Unabhängigkeit}) \\
&= \frac{1}{n^2} \cdot n \cdot [p_0(1-p_0)] = \frac{p_0(1-p_0)}{n}
\end{aligned}
\] Der Standardfehler von \(p_0\) ist folglich: \[
SE_{p_0} = \sqrt{\frac{p_0(1-p_0)}{n}}
\] Auch die Länge des KIs ist nicht nur vom Standardfehler von \(p_0\) abhängig, sondern noch zusätzlich vom Stichprobenumfang. Wir sehen aber, dass dieser Einfluss mit steigendem \(n\) immer kleiner wird. Wenn die Stichproben sehr gross werden
Bei beiden Eingangs hatten wir für die Normalverteilungsannahme die Gültigkeit des Zentralen Grenzwertsatzes (ZGS) angeführt. Wann kann ich das näherungswiese annehmen? Wir orientieren uns an folgender Faustregel.
WarnungFaustregel für die Normalapproximation des Wilson-Intervalls
Die Approximation durch die Normalverteilung (also den ZGS) ist nur verlässlich, wenn die Stichprobe gross genug ist und der Anteilswert nicht zu nah an 0 oder 1 liegt. Als Daumenregel gilt:
\[ n \cdot (1-\hat{p}) \geq 5\]
Verständnisfrage 5:
Ein Server hat eine sehr niedrige Fehlerquote von \(\hat{p} = 0.004\). Sie erheben eine Stichprobe von \(n = 200\) Anfragen. Darf die Normalapproximation für das Konfidenzintervall verwendet werden?
a) Ja, denn \(n = 200\) ist gross genug für den Zentralen Grenzwertsatz.
b) Nein, denn \(n \cdot \hat{p} = 0.8 < 5\), die Faustregel ist verletzt.
c) Ja, denn der wahre Anteilswert \(p_0\) ist unbekannt und die Faustregel gilt nur für bekannte Werte.
d) Nein, denn Fehlerquoten können grundsätzlich nicht normalverteilt sein.
Antwort anzeigen
Richtige Antwort: b) Die Bedingung \(n \cdot \hat{p} \geq 5\) ist verletzt. Bei sehr kleinen Anteilswerten nahe 0 (oder 1) ist die Binomialverteilung stark asymmetrisch und die Normalapproximation unzuverlässig.
Schauen wir nochmals zurück und erinnern uns, dass beim Erwartungswert der Standardfehler die Länge des KIs definiert haben. Dies ist hier viel komplizierter. Überlegen wir, wie der Standardfehler beim Anteilswert ausgerechnet wird.
Herleitung des Standardfehlers für Anteilswerte
Da \(\hat{p}\) mathematisch gesehen ein Mittelwert von \(n\) i.i.d. Bernoulli-Variablen ist, können wir die Varianz von \(\hat{p}\) analog zur Herleitung bei metrischen Daten bestimmen:
Der theoretische Standardfehler (SE) ist die Standardabweichung dieses Schätzers, also:
\[
SE_{p_0} = \sqrt{\frac{p_0(1-p_0)}{n}}
\]
Da wir in der Praxis \(p_0\) in der Regel nicht kennen, nutzen wir den Schätzer \(\hat{p}\) aus unserer Stichprobe für die Schätzung:
Konstruktion des Konfidenzintervalls (sog. Wald-Intervall)
Nach dem Zentralen Grenzwertsatz ist \(\hat{p}\) bei ausreichend großem \(n\) näherungsweise normalverteilt. Dies ist die gleiche Argumentation wie beim Mittelwert vorher. Wir können daher die bekannte Struktur für das Konfidenzintervall anwenden:
\[\hat{p} \pm z_{1-\alpha/2} \cdot \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\] Die Standardabweichung zusammen mit der Quantile zu \(1 -\alpha/2\), \(z_{1-\alpha/2}\) bestimmt, wie lang das KI wird, welches wieder symmetrisch zum Anteilswert der zughörigen Stichprobe ist.
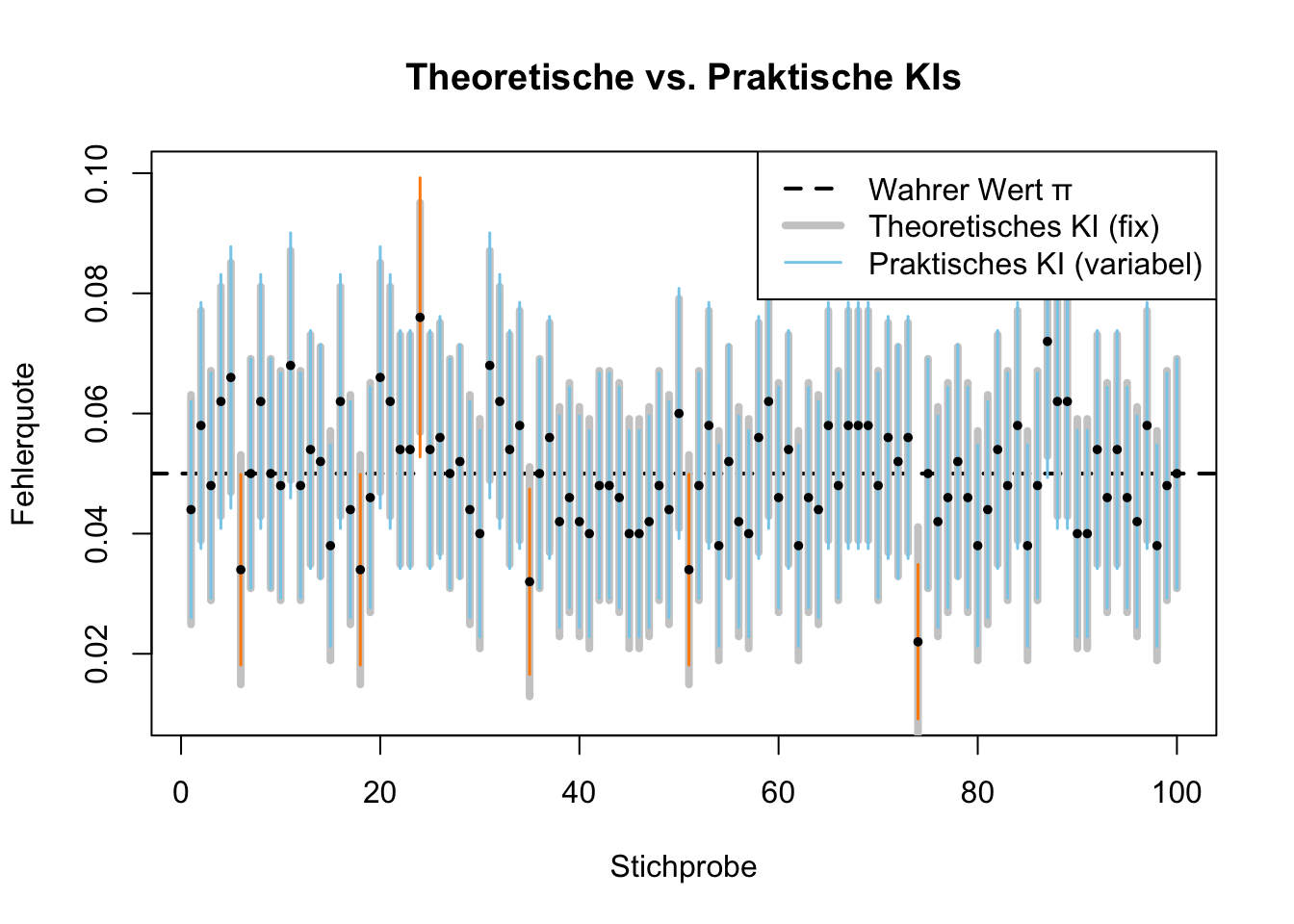
Simulation: Fehlerquoten in der Praxis
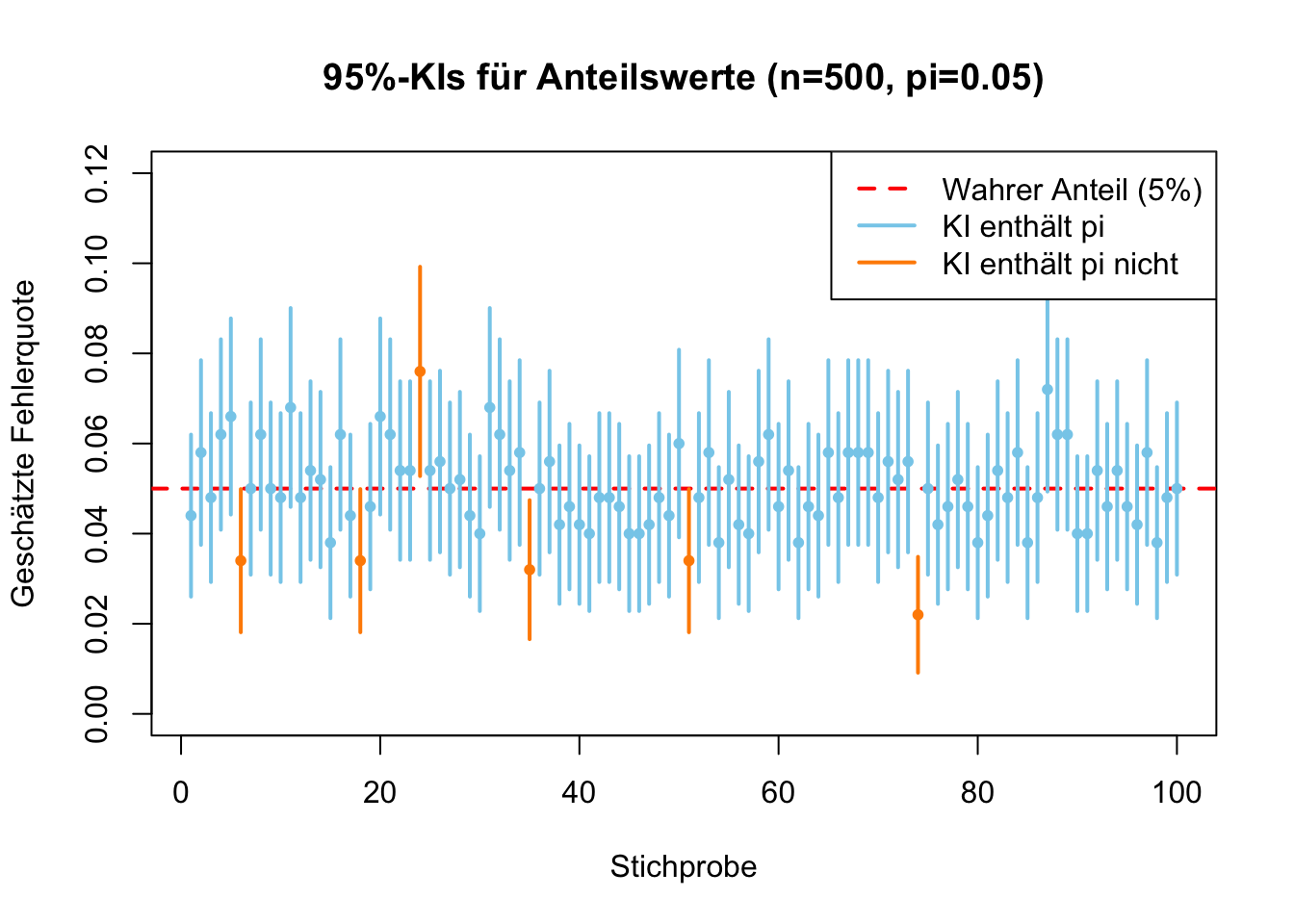
Wir simulieren eine Server-Fehlerquote von \(\pi = 0.05\) (\(5\%\)) und ziehen 100 Stichproben mit jeweils \(n=500\) Anfragen mit realistischen Annahmen.
Vergleich der Intervalle: Die grauen Linien (theoretisch) sind konstant, die farbigen (praktisch) variieren je nach Stichprobenergebnis.
Wir sehen, dass in der Praxis die Länge der KIs variiert beim Wald-Intervall, weil jede Stichprobe eine andere Schätzung des Anteilswertes liefert. Diese beeinflusst direkt den Standardfehler und führt zu den unterschiedlichen Längen.
Interpretation von Konfidenzintervallen des Anteilswertes
Wie arbeiten und interpretieren wir diese Intervalle in der Praxis?
Analog zum Erwartungswert werden wir in der Praxis nur eine einzige Stichprobe erheben. Angenommen wir schicken \(n = 500\) Anfragen an unseren Server und beobachten \(41\) Fehler, also \(\hat{p} = 41/500 = 0.082\). Den Standardfehler schätzen wir aus der Stichprobe:
Wenn wir das KI einmal bestimmt haben, enthält es den wahren Anteilswert \(p_0\) oder eben nicht. Nach der Messung gibt es keine Wahrscheinlichkeitsaussage mehr für dieses einzelne Intervall — alles ist festgelegt.
Korrekt sagen wir deshalb:
„Das Verfahren, mit dem dieses Intervall\([0.058,\; 0.106]\) konstruiert wurde, liefert bei wiederholter Anwendung in \(95\%\) aller Fälle ein Intervall, das den wahren Anteilswert \(p_0\) enthält.”
Praktische Anwendung: Überwachung der Fehlerquote
Nehmen wir an, unser Server wurde bei Inbetriebnahme auf eine Fehlerquote von \(\pi_0 = 0.05\) (\(5\%\)) kalibriert und abgenommen. Nach drei Monaten Produktionsbetrieb führen wir eine Stichprobenmessung durch und erhalten \(KI = [0.058,\; 0.106]\). Wie interpretieren wir diesen Befund?
Der ursprüngliche Wert \(\pi_0 = 0.05\) liegt nicht im Konfidenzintervall. Wir wissen, dass vor jeder Messung eine \(95\%\)-ige Wahrscheinlichkeit bestand, dass das zu bestimmende KI den wahren Wert enthält. Liegt \(\pi_0\) dann nicht darin, können wir festhalten, dass dieser Fall ursprünglich nur mit \(5\%\) Wahrscheinlichkeit eintreten sollte. Die Vermutung liegt deshalb nahe, dass sich die Fehlerquote des Servers tatsächlich erhöht hat — nicht bloss durch Zufall.
WichtigUnterschied zum Erwartungswert
Beim Erwartungswert war das KI stets symmetrisch um \(\bar{x}\) und hatte eine feste Länge, weil der Standardfehler \(\sigma/\sqrt{n}\) nicht von der Stichprobe abhängt (sofern \(\sigma\) bekannt). Beim Anteilswert hingegen hängt der Standardfehler \(\sqrt{\hat{p}(1-\hat{p})/n}\) direkt von \(\hat{p}\) ab — jede Stichprobe liefert deshalb ein KI mit unterschiedlicher Länge. Das KI ist zudem nur für \(\hat{p}\) weit genug von \(0\) und \(1\) entfernt verlässlich (Faustregel: \(n\hat{p} \geq 5\)).
Dieses Vorgehen findet sich häufig im Software-Qualitätsmanagement: Dort werden Fehlerraten (z.B. Anteil fehlgeschlagener Deployments, Anteil fehlerhafter API-Antworten) periodisch gemessen und gegen einen bei der Inbetriebnahme definierten Zielwert geprüft. Liegt dieser Zielwert ausserhalb des aktuellen KIs, ist dies ein statistisches Signal für eine Verschlechterung — analog zur Kalibrierungsprüfung einer Abfüllanlage beim Erwartungswert.
Konfidenzintervalle mit R berechnen
Bisher haben wir R als Taschenrechner eingesetzt: Wir haben die Formeln Schritt für Schritt selbst implementiert, um die Herleitung nachzuvollziehen. In der Praxis stellt R jedoch fertige Funktionen zur Verfügung, die das gesamte KI in einer einzigen Zeile berechnen — inklusive korrekter Verteilung, Freiheitsgraden und Ausgabe. Wir wenden diese auf unsere beiden Serverbeispiele an.
KI für den Erwartungswert: t.test()
Für metrische Daten mit unbekannter Varianz — also dem Regelfall der Praxis — liefert t.test() direkt das Konfidenzintervall auf Basis der t-Verteilung. Wir simulieren eine Stichprobe von \(n = 100\) Antwortzeiten aus unserem Servermodell (\(\lambda = 5\), wahrer Erwartungswert \(\mu = 0.2\,s\)):
One Sample t-test
data: antwortzeiten
t = 7.4699, df = 99, p-value = 3.218e-11
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
0.1651326 0.2845915
sample estimates:
mean of x
0.2248621
Die Ausgabe enthält das \(95\%\)-KI direkt. Für die weitere Verarbeitung lassen sich die relevanten Grössen einzeln extrahieren:
In unserer manuellen Herleitung haben wir mit der bekannten Populationsvarianz \(\sigma^2 = 1/\lambda^2\) gerechnet und deshalb die Normalverteilung verwendet. t.test() schätzt die Varianz aus der Stichprobe (\(s^2\)) und verwendet korrekt die t-Verteilung mit \(n-1 = 99\) Freiheitsgraden. Das ist in der Praxis der Standardfall — \(\sigma\) ist selten bekannt. Die KI-Grenzen weichen daher leicht von der manuellen Berechnung ab, sind aber statistisch präziser.
KI für den Anteilswert: prop.test()
Für Anteilswerte steht prop.test() zur Verfügung. Wir verwenden unser Messbeispiel: \(41\) Fehler bei \(n = 500\) Anfragen. Das Argument correct = FALSE liefert das Wilson-Intervall ohne Stetigkeitskorrektur — also genau die Variante, die wir hergeleitet haben:
Code anzeigen
ergebnis_p <-prop.test(x =41, n =500, conf.level =0.95, correct =FALSE)ergebnis_p
1-sample proportions test without continuity correction
data: 41 out of 500, null probability 0.5
X-squared = 349.45, df = 1, p-value < 2.2e-16
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.06101909 0.10935486
sample estimates:
p
0.082
prop.test() bietet zwei Varianten, die sich nur in der Stetigkeitskorrektur unterscheiden:
correct = FALSE — reines Wilson-Intervall, wie hergeleitet
correct = TRUE(Standard) — Wilson-Intervall mit Stetigkeitskorrektur nach Yates; etwas konservativer (breiteres KI), empfohlen bei kleinen \(n\)
Für sehr kleine Stichproben oder Anteilswerte nahe \(0\) oder \(1\), wo die Faustregel \(n\hat{p} \geq 5\) verletzt ist, empfiehlt sich stattdessen binom.test(). Es berechnet das exakte Clopper-Pearson-Intervall auf Basis der Binomialverteilung — ohne jede Normalapproximation:
Code anzeigen
binom.test(x =41, n =500, conf.level =0.95)
Exact binomial test
data: 41 and 500
number of successes = 41, number of trials = 500, p-value < 2.2e-16
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.05948546 0.10959894
sample estimates:
probability of success
0.082
Vergleich der Methoden
Die drei Varianten für Anteilswerte liefern bei grossen Stichproben nahezu identische Ergebnisse, unterscheiden sich aber bei kleinen \(n\) oder extremen \(\hat{p}\) deutlich. Der folgende Code stellt alle drei nebeneinander:
Code anzeigen
x <-41; n <-500# Wald-Intervall (manuell, wie hergeleitet)p_hat <- x / nse <-sqrt(p_hat * (1- p_hat) / n)wald <-c(p_hat -1.96* se, p_hat +1.96* se)# Wilson-Intervall (prop.test ohne Korrektur)wilson <-prop.test(x, n, correct =FALSE)$conf.int# Exaktes Clopper-Pearson-Intervallexakt <-binom.test(x, n)$conf.int# Ausgabe als Tabelledata.frame(Methode =c("Wald", "Wilson", "Clopper-Pearson (exakt)"),Untergrenze =round(c(wald[1], wilson[1], exakt[1]), 4),Obergrenze =round(c(wald[2], wilson[2], exakt[2]), 4))
Bei \(n = 500\) und \(\hat{p} = 0.082\) sind die Unterschiede gering. Je kleiner \(n\) oder je näher \(\hat{p}\) an \(0\) oder \(1\), desto stärker weicht das Wald-Intervall von den robusteren Alternativen ab.